FastCommit论文精读
Introduction
FastCommit是一种文件系统的日志机制,主要针对传统物理日志方式(JBD2 ..)等存在的高磁盘写带宽占用、高IO占用和上下文切换开销等问题进行优化。
核心desgin:
- compact journaling
- selective flusing
- inline journaling
FastCommit相比于JBD2 吞吐量提升120%并成功整合到Upstream Linux Kernel中。
Background
Physical Journaling vs Logical Journaling
逻辑日志只记录文件或者目录的修改操作。物理日志记录了变化的元数据(bitmaps, directory entries…), 并在checkpoint或者crash recovery的时候写回disk。
大部分文件系统都是用了物理日志,因为物理日志方柏霓使用,文件系统格式不敏感并且容易维护。但是物理日志一般体量较大
逻辑日志的size较小并且记录日志的速度快,但是他的崩溃恢复机制比较复杂并且很慢(因为需要对文件操作进行重放)。
JBD2 Journaling
JBD2是最常用的物理日志方式,被大多数文件系统采用。它通过提交一个事务的方式来对多个块进行以此更新。在checkpoint可以异步的将其存储的元数据写入磁盘。
NFS protocol and semantics.
NFS protocol and semantics.
Close-to-Open Consistency Mechanism
NFS(Network File System)中的 ### ### Close-to-Open Consistency Mechanism
NFS(Network File System)中的 close-to-open 机制是一种确保文件一致性的策略。其主要目标是在文件关闭(close)和重新打开(open)之间保持文件数据的一致性。具体包括以下几个步骤:
文件关闭(Close):
- 当客户端关闭一个文件时,NFS 客户端会将所有对该文件的修改(写操作)同步到服务器,确保服务器上的文件数据是最新的。
文件打开(Open):
- 客户端重新打开文件时,NFS 客户端会检查服务器上的文件是否有更新。如果服务器上的文件自上次客户端缓存以来发生变化,客户端会丢弃缓存,并从服务器重新读取文件数据。
通过该机制,NFS 保证文件在关闭和重新打开之间的修改能够被检测和同步,从而提高了文件系统的一致性。这在多客户端同时访问和修改同一文件的分布式环境中尤为重要。
Motivation
JBD2多次频繁的commit导致效率低下
JBD2每5秒就要提交一次并且每次都会触发fsync。
每次JBD2提交至少存储3个块(4KB)——一个描述符块(关于提交中其他块的元数据),至少一个已更改的元数据块,以及一个表示提交结束的提交标记块。
每次JBD2提交至少需要两个写IOs——一个写描述符块以及已更改的元数据块到磁盘,另一个写提交标记块。
NFS的一致性保证不适用于JBD2
NFS 的异步模式语义会将每个 create + append + close 操作转换为 create + append + close + fsync。因此,对于 JBD2 而言,默认的 NFS 不会频繁地将大型提交转换为 fsync-on-close。然而,如果使用的是同步模式的 NFS,上述操作会被转换为 create + fsync、append + fsync 和 close + fsync,这就导致了性能上的异常情况。
与云环境的收费机制之间的矛盾
高字节和IO开销:JBD2在进行大量元数据操作时,会产生大量的字节和IO开销,尤其是在频繁的fsync调用下。这在云环境中会导致更高的成本,因为云存储通常基于使用量收费(如IOPS和吞吐量)。
成本影响:由于JBD2的高开销,用户在云中使用Ext4文件系统时,可能需要购买更多的存储性能(如更高的IOPS和带宽)以满足性能需求,从而增加了整体成本。
Main Idea
FastCommit的目标是减少日志的byte和IO的overhead,以此来减少资源消耗并提高用户的使用体验。
他的核心idea就是混合使用logical journaling 和 physical journaling。FastCommit不修改JBD2每5秒commit一次的设计,但是在这5s中间,FastCommit会去尝试进行logical journaling,但是如果无法进行logical journaling(通常是一些比较少见的操作比如文件系统的resize等),则退回到传统的JBD2的方式。
Desgin
Hybrid Jounraling
像JBD2这样的物理日志被设计为在块级别提供日志记录。另一方面,逻辑日志记录文件和目录操作,这些操作位于inode级别,而不是块级别。因此,FASTCOMMIT的混合日志需要在两个级别上都支持日志记录和恢复,而不会造成分层冲突。
The FASTCOMMIT commit
首先介绍一下在俩次slow commit之间FastCommit做了什么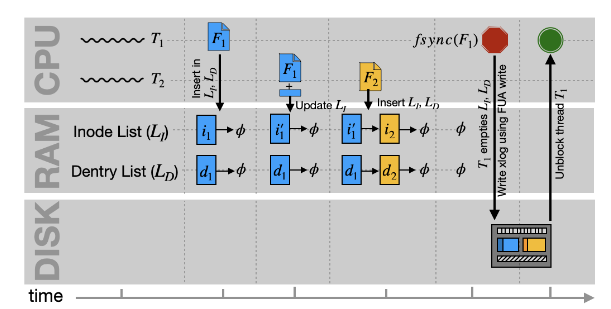
这里作者举了例子来说明FastCommit的操作过程:
- 首先FastCommit维护了俩个In-Memory的List:LI和LD,LI用来记录inode的更新;LD用来记录目录条目的更新。
- 假设有个线程T1创建了一个新的文件F1,那么像LI中插入新分配的inode;向LD中插入新的目录条目。
- 假设后续线程T2向文件F1中追加了数据,这里和传统的JBD2的区别就出现了:JBD2会存储完整的被修改的元数据快的副本,而FastCommit进存储被修改的数据块的中被涉及的部分的偏移量。如图中所示i1更新为i1’。
- 随后线程T2创建新文件F2,对应的inode和目录条目也被更新进俩个list中。
- 随后线程T1发起fsync操作,FastCommit遍历俩个list,将所有的更新到宝成一个FCLog并将其存储到FC area。通常一个FCLog可以容纳进一个4KiB的磁盘块中。
FCLog

前面提到,FastCommit在线程调用fsync后会把所有文件更新大包围一个FCLog并写入到FC area,注意这里FC area并没有新开辟任何空间,而是在JBD2的原本存放日志的位置占用了15%的space,所以没有引入额外的overhead。
每个FCLog记录了多个文件的更新操作,是由多个FCTag组成的,每个FCTag包含三个部分:
- type(2 Bytes)
- length(2 Bytes)
- value(variable length)
FCLog总是以头标记开始,以尾标记结束,它们都占用12个字节。head标记标志着FASTCOMMIT提交的开始,并包含前一个慢提交的提交ID,之后应该重播这个FCLog以备恢复。tail标记标志着FCLog的结束(类似于传统JBD2提交中的提交块)。
注意大部分的文件操作都可以用8个FCTags来描述:
- HEAD: 标志一个FCLog的开始
- ADD_RANGE: 在一个文件中添加数据
- DEL_RANGE: 在一个文件中删除数据
- CREAT: 创建一个文件
- LINK: 符号链接或重命名文件
- UNLINK: 删除一个文件
- INODE: 存储一个inode
- TAIL: FCLog的结尾并包含一个checksum
可以举几个例子来说明如何用FCTags来记录文件操作。
- 文件创建/删除:这个操作创建了一个包含俩个FCTags的FCLog。CREATE和INODE,CREATE表明这是一个文件创建操作,INODE则存储了一个新的Inode的副本。
- 向文件中追加内容:我们考虑向一个叫做foo的文件中添加4KiB的数据,这个操作会产生一下的FCTags:
- HEAD Tags (12Bytes)
- ADD_RANGE FCTag (20 bytes)表示在文件中添加了一个逻辑块地址为1、物理块地址为1000、大小为1块的新区段。
- INODE FCTag (136 bytes):文件inode的最新副本。
- TAIL FCTag (12 bytes).
整个FCLog的开销是168Bytes,首先说一下inode的136Bytes的构成:INODE FCTag 的大小为 136 字节,主要是由于 inode 结构中包含了多个字段,每个字段占用一定的字节数。以下是详细的计算过程:
inode 结构组成及字节分配:
- 文件类型和权限(mode):4 字节
- 用户ID(UID):4 字节
- 组ID(GID):4 字节
- 文件大小(size):8 字节
- 访问时间(atime):8 字节
- 修改时间(mtime):8 字节
- 更改时间(ctime):8 字节
- 链接计数(nlink):4 字节
- 块指针(block pointers):
- 直接指针:48 字节(假设有12个直接指针,每个指针4字节)
- 间接指针:32 字节(例如,单、双、三重间接指针,每个指针4字节)
- 扩展属性(extended attributes):16 字节
- 校验和(checksum):8 字节
具体计算
| 字段 | 字节数 |
|---|---|
| mode | 4 |
| UID | 4 |
| GID | 4 |
| size | 8 |
| atime | 8 |
| mtime | 8 |
| ctime | 8 |
| nlink | 4 |
| 块指针(直接 + 间接) | 80 |
| 扩展属性 | 16 |
| 校验和 | 8 |
| 总计 | 136 |
解释
- 块指针:通常,一个 inode 包含多个直接和间接块指针,用于指向文件的数据块。假设有12个直接指针,每个4字节,共48字节;再加上单、双、三重间接指针,每个4字节,共32字节,总计80字节。
- 扩展属性:用于存储文件的附加信息,如SELinux标签等,占用16字节。
- 校验和:用于确保 inode 数据的一致性和完整性,占用8字节。
通过以上字段的累加,总大小为136字节,因此 INODE FCTag 需要136字节来记录 inode 的最新副本。
而同样的操作JBD2则需要24KiB来完成。这是因为:
- 一个文件描述快(4KiB)
- 修改的元数据快:
- inode(4KiB)
- 目录entry(4KiB)
- 块位图(4KiB)
- 扩展树块(4KiB)
- 提交标记块(4KiB)
- 在文件中删除数据:FastCommit只记录被删除文件所属的一个区段在DEL_RANGE中。当FASTCOMMIT记录了DEL_RANGE标签中的逻辑块范围后,删除操作会更新inode以反映文件当前的块分配状态。在恢复过程中,可以通过解析最新的inode状态来推断出哪些物理块已被释放或删除,而无需在日志中显式存储这些物理块地址。
- 重命名文件:假设文件“/foo”要重命名为“/bar”。让我们假设目录条目“/foo”与磁盘上的inode i10相关联。重命名操作将生成以下FCTags:
- HEAD FCTag (12 bytes).
- LINK FCTag that records the association of “bar” with i10 (16 bytes).
- UNLINK FCTag that records the disassociation of the directory entry “foo” from i10 (16 bytes).
- INODE FCTag that records the most recent copy of inode i10 (136 bytes).
- TAIL FCTag (12 bytes).
因此,rename的整个FASTCOMMIT提交被捕获为192字节。在JBD2中,重命名操作需要存储7个大小为4KB的块,每个块总共28KB。
当将文件 /foo 重命名为 /bar 时,涉及以下操作:
- 描述符块(4KB):
记录此次重命名操作的基本信息。 - 修改的元数据块(4KB × 5 = 20KB):
- inode 块:更新 /foo 和 /bar 的 inode 信息。
- 目录条目块:更新旧目录 /foo 中的条目,移除对 inode i10 的引用。
- 新目录条目块:在新目录 /bar 中创建新的目录条目,指向 inode i10。
- 块位图块(Block Bitmap):如果有块分配或释放,需要更新块位图。
- 扩展树块(Extent Tree Block):如果涉及扩展属性,还需要更新扩展树。
- 提交标记块(4KB):
Selective Flushing
Cache flush命令强制磁盘将写入易失性Cache中的数据全部写入非易失性介质。文件系统广泛使用刷新来保证数据的一致性。但是,如果日志子系统在决定何时进行刷新时不小心,它可能会将数据刷新到磁盘,而这些数据本可以安全地在磁盘缓存中驻留更长时间。
以JBD2为例,JBD2首先用写入实际数据和文件操作设计的元数据,为了确保数据全部持久化就需要一次flush,之后还需要写一个commit block来标志这个commit结束,但这里不需要flush而是用一个FUA跳过页缓存直接写入磁盘。但注意FUA一次只能写入一个block。
我的理解是,FastCommit设计的FCLog大部分情况下都可以容纳进一个block里面,那么就可以直接用FUA写入从而避免flush的时间,对于那些无法用logical journal的情况就退回到JBD2的机制,所以叫做selective flushing。
Inline Jounarling
这里感觉论文写的并不是很清楚,大概意思是说FastCommit可以把journal做的很小,然后就不需要切换到JBD2的线程来进行commit,因此少了俩次上下文切换的开销,换来了一些吞吐量。